AI 原生项目为什么适合用 Python 做后端:从 Web 工作台到专业能力内核
做 AI 原生项目越多,我越明显地感受到一件事:Python 做后端,不只是“接模型方便”,它在很多专业系统里其实很有扩展性。
这种扩展性不只是多装几个 AI SDK,也不只是把大模型接口包一层。真正有价值的地方在于:Python 很适合承载那些会不断增长、不断试验、不断验证的专业能力。
做了很多年 Java 之后,我对“稳”这件事有很深的执念。
在传统企业系统里,Java 后端、分层架构、事务边界、权限模型、审计日志,这一整套工程方法仍然非常可靠。它的问题从来不是“不能做”,而是在某些新型产品里,它不一定是最轻、最快、最贴合问题本身的做法。
真正让我改变判断的,不是某个新框架,也不是“AI 时代必须换栈”这种口号,而是 ArchSight Solver 结构力学求解器和 ArchSight Compliance 筑见合规这类建筑 AI 与工程软件产品暴露出来的一组新约束:
- 页面不是简单表单,而是工程工作台;
- 后端不是普通 CRUD,而是专业计算、文档解析、知识检索和证据链;
- 用户不只看一个结果,还要能复核过程、导出报告、回到算例;
- 系统不只要“跑通”,还要能被工程师、教师、审查人员反复验证。
所以这次架构调整的核心,并不是“从 Java 换成某个更潮的技术栈”,而是一个更朴素的判断:
AI 原生工程软件不应该只有一个大后端。它更适合被拆成 Web 工作台和 Python 专业内核。
一、问题变了:这不是传统业务系统
如果只是做审批、台账、报表、用户权限和流程流转,我仍然会很自然地想到 Java。它的生态、治理能力和团队可维护性都很成熟。
但 ArchSight 面对的问题更接近“工程软件 + AI 平台”的交叉地带。
以已经公开的 ArchSight Solver 结构力学求解器为例,它不是一个展示页面,也不是一个简单计算器。用户需要在浏览器里完成建模、设置荷载、运行分析、查看内力图和位移曲线,最后导出 Word / Excel 计算书。
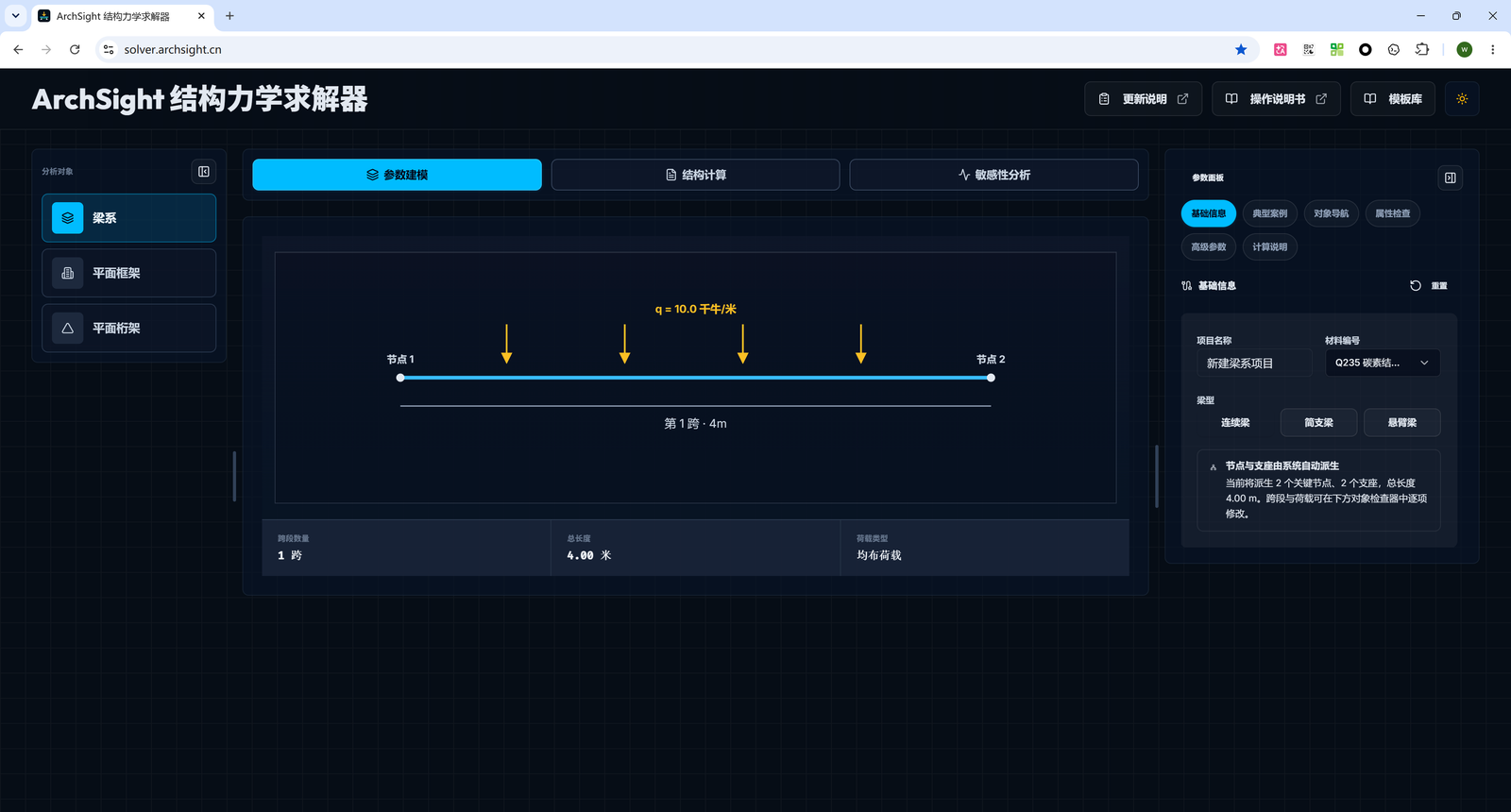
这类产品的复杂度,不在于某个按钮怎么写,而在于三个东西必须同时成立:
- 交互要快:参数修改、图形反馈、结果切换不能笨重。
- 计算要准:梁系、平面框架、平面桁架这些专业计算必须可复核。
- 过程要留痕:输入、图形、结果、导出物和基准算例之间要能互相对上。
这和传统企业系统的重心很不一样。
传统系统更关心“流程是否闭环”;工程软件更关心“模型、计算和证据是否一致”。ArchSight Compliance 筑见合规也是类似逻辑:规范摄取、条文结构化、图谱检索、向量检索、规则推理、证据链展示和人工复核,核心都不是普通 CRUD。
这时,如果还把所有东西都塞进一个厚重业务后端里,系统当然能做,但边界会越来越拧巴。
二、我真正想拆开的,是两类复杂度
过去我们常说“前后端分离”。但在 AI 原生工程软件里,只做前后端分离还不够。
真正应该拆开的,是两类完全不同的复杂度:
| 层次 | 主要负责 | 典型问题 | | --- | --- | --- | | Web 工作台 | 页面交互、工程图形、状态组织、结果浏览、用户操作闭环 | 用户如何建模、如何复核、如何切换视图 | | Python 专业内核 | 专业计算、AI 推理、文档解析、检索增强、报告导出、基准验证 | 结果是否正确、过程是否可追溯、算法是否可验证 |
这不是为了追求“前端漂亮、后端先进”,而是为了让不同类型的问题待在合适的位置。
Web 工作台天然适合承载高频交互。它可以把参数面板、结构图、荷载图、结果曲线、模板库和导出入口组织在一个连续体验里。
Python 专业内核天然适合承载专业能力。结构计算、数值库、文档生成、AI 工具链、知识检索和批处理任务,都更容易在 Python 生态里快速组合、验证和迭代。
在这个边界下,Web 层不假装自己懂专业算法;Python 层也不被迫承担大量页面状态和交互细节。两边通过 API、数据契约和测试基准协作。
三、为什么 Python 后端在 AI 项目里更有扩展性
这里必须说清楚:我不是认为 Java 不适合严肃系统。
恰恰相反,Java 在很多严肃系统里仍然是最稳的选择。权限、交易、流程、审计、组织架构、复杂业务一致性,这些场景 Java 依然很强。
但 ArchSight Solver 结构力学求解器和 ArchSight Compliance 筑见合规这类产品当前最难的地方,不是把一个已知业务流程做得更稳,而是快速把专业能力产品化:
- 一个结构力学算例,能不能从参数建模走到图形展示;
- 一个计算结果,能不能同时给出反力、内力、位移和控制位置;
- 一个工程场景,能不能导出接近交付习惯的计算书;
- 一个 AI 审查结论,能不能追溯到条文、证据和人工复核意见;
- 一个算法修改,能不能通过基准算例和回归门禁证明没有破坏旧结果。
这些问题的重心不是“业务后端写得多规范”,而是“专业内核能不能被快速验证”。
如果用 Java 承载全部能力,就会遇到两个现实问题:
第一,专业计算和 AI 生态的组合成本更高。很多数值计算、文档解析、AI 编排、向量检索和报告生成工具,在 Python 里更直接。
第二,产品迭代会被后端分层惯性拖慢。工程工作台里的很多变化来自使用体验和专业验证过程,未必适合每一步都按传统企业应用的厚重分层推进。
Python 后端的扩展性,恰恰体现在这些地方:
- 可以从一个计算接口扩展到一组专业引擎;
- 可以从单次请求扩展到异步任务、批处理和报告生成;
- 可以从规则判断扩展到图谱检索、向量检索和 AI 推理;
- 可以从内部验证脚本扩展到基准算例、回归测试和工程门禁;
- 可以把开源库、专业算法、模型服务和文档工具链组合成一个持续演进的能力层。
这类扩展不是传统意义上的“业务模块变多”,而是专业能力不断沉淀。对 AI 项目来说,这往往比普通 CRUD 扩展更重要。
所以我现在更倾向于把 Java 的经验保留下来,但不把 Java 的形态完整搬过来。
保留下来的是什么?边界意识、契约意识、测试意识、审计意识、工程可维护性。
放下的是什么?为了“看起来严肃”而保留的过厚层级和过早平台化。
四、Web 工作台负责“让专业能力可使用”
Web 工作台不是传统意义上的“前端页面”。
在 ArchSight Solver 结构力学求解器里,它至少承担了五件事:
- 让用户选择梁系、平面框架、平面桁架等分析对象;
- 用参数面板表达跨度、支座、材料、荷载等工程输入;
- 用结构图和结果图帮助用户理解模型;
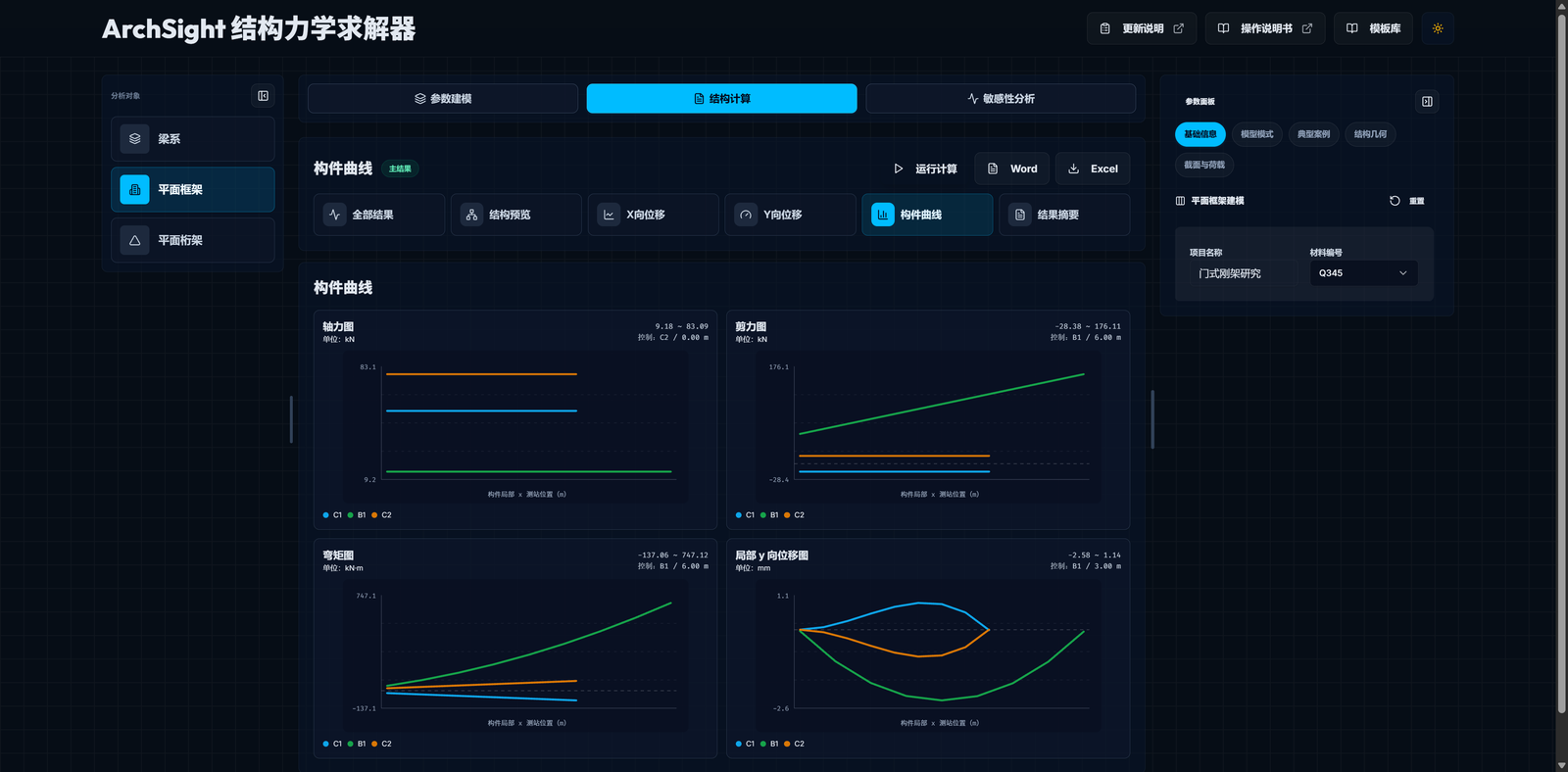
- 在多个结果视图之间切换,例如反力、弯矩、剪力、位移;
- 把计算、敏感性分析、模板库和导出操作组织成一个闭环。
这也是为什么我现在更愿意把它叫作“工作台”,而不是“前端”。
“前端”这个词容易让人误解成皮肤、页面和样式;“工作台”强调的是使用者完成工作的地方。对于工程软件来说,浏览器里的工作台必须尊重专业对象,而不是只做漂亮布局。
这也是我不再强行强调 Next.js 的原因。
如果产品主战场是内容站、SEO、服务端渲染和营销页面,Next.js 很合适。但 ArchSight 当前这些工作台型产品,核心不是首屏 SEO,而是复杂交互、图形渲染、局部状态、计算结果复核和专业工作流。
在这个阶段,React + Vite 这类更直接的 Web 应用形态,反而更贴合。
五、Python 内核负责“让专业能力可信”
Web 工作台解决“怎么用”,Python 专业内核解决“算得对不对、证据靠不靠谱”。
以 ArchSight Solver 结构力学求解器为例,Python 后端承担的是连续梁、二维平面框架、二维平面桁架等分析能力,以及 Word / Excel 计算书导出、基准算例和错误契约。
这类能力的关键词不是“接口数量”,而是“可信”:
- 输入参数要明确;
- 计算假设要清楚;
- 输出结果要可解释;
- 图形和数值要能对上;
- 导出物要能被复核;
- 算法修改要能被回归测试拦住。
在 ArchSight Compliance 筑见合规这类未公开产品里,专业内核还会延伸到规范资料摄取、条文结构化、图谱和向量检索、合规任务、报告、审计记录和人工复核闭环。
这些都不是普通页面逻辑。它们更接近“领域引擎”。
所以 Python 在这里不是脚本补丁,而是专业能力的主承载层。
六、这套架构真正的边界
如果只说“Web + Python”,仍然太粗。真正决定系统能不能长期演进的,是边界怎么划。
我现在会用四条规则约束这类产品:
第一,Web 工作台不实现专业算法。
它可以做输入校验、单位提示、交互预览,但核心计算必须回到专业内核。否则算法会散落在页面组件里,后续很难复核。
第二,Python 内核不关心页面长什么样。
它关心的是输入契约、计算过程、输出结构和错误语义。不要让专业内核被页面状态污染。
第三,跨层通信必须有稳定数据契约。
无论是结构计算请求,还是合规审查任务,都应该有清晰的输入输出结构。否则前端改一点、后端补一点,很快就会变成靠人肉记忆维持。
第四,专业结论必须能被测试和导出物验证。
工程软件不能只相信“页面显示成功”。基准算例、回归测试、导出计算书、结果摘要,这些都是专业可信度的一部分。
这四条边界,其实都是 Java 架构经验的延续,只是落在了新的技术组合上。
七、这套方案也有代价
我不想把这套架构写成万能答案。
Web 工作台 + Python 专业内核会带来新的复杂度:
- 前后端契约需要认真维护;
- 长任务、文件上传、导出任务和错误恢复要设计清楚;
- Python 内核不能因为“写起来快”就变成无结构脚本;
- Web 工作台不能因为“交互灵活”就把业务规则写散;
- 部署、日志、监控和回归验证都要形成基本工程纪律。
所以这不是“轻松替代 Java”的方案,而是一种更适合当前产品形态的分工方式。
如果团队没有契约意识、测试意识和工程边界,换成任何技术栈都会失控。AI 时代尤其如此,因为 AI 会把代码生成速度拉得很快,也会把结构熵增放得更大。
八、给 AI 项目选后端的判断清单
如果你也在做 AI 原生产品或工程软件,我建议不要先问“哪个技术栈最先进”,而是先问几个更具体的问题:
- 你的系统核心价值,是流程闭环,还是专业计算、AI 推理和证据复核?
- 用户主要是在填表审批,还是在一个工作台里持续建模、查看、调整和导出?
- 算法和 AI 能力是否需要频繁试验、回归验证和快速替换?
- 页面状态是否已经复杂到需要把交互体验作为一等公民设计?
- 你的专业结论是否需要导出、复核、审计和基准算例证明?
如果答案更多偏向后者,那么“Web 工作台 + Python 专业内核”可能比一个完整大后端更自然。
但如果你的核心仍然是交易一致性、复杂组织权限、稳定流程和大规模企业集成,Java 仍然可能是更好的主力。
关键不是技术站队,而是让架构形态服从问题本身。
结语
做 AI 原生项目,我最大的变化不是“换了一套技术栈”,而是对系统边界有了新的理解。
过去我更习惯从后端中心看系统:领域模型、服务层、数据库、接口、权限。
现在我会先看这个产品到底在完成什么工作:是让用户走完流程,还是让专业能力被使用、被验证、被复核、被交付。
对 ArchSight 这类建筑 AI 和工程软件来说,答案越来越清楚:
- Web 工作台负责让专业能力变得可操作;
- Python 专业内核负责让专业结论变得可信;
- 数据契约、基准算例和导出物负责把两者连接成可验证闭环。
这不是对 Java 的背叛,而是把多年的工程经验换一种形态继续使用。
访问 ArchSight Solver 结构力学求解器:https://solver.archsight.cn