ArchSight Cognition 开源:给 AI Agent 一套可复用的跨学科思维工具
最近,ArchSight Labs 开源了一个新项目:ArchSight Cognition。
项目地址:https://github.com/ArchSightLabs/archsight-cognition npm 包地址:https://www.npmjs.com/package/@archsight/cognition
它关注的是一个更基础的问题:
当 AI Agent 开始参与写作、决策、研究、产品评审和工程判断时,它应该用什么思维方式看问题?
它不是一个应用程序,也不是一个新的 Agent Runtime,更不是“名人角色扮演”提示词集合。
更准确地说,ArchSight Cognition 是一组给 AI Agent 使用的跨学科思维工具。它把哲学、文学、历史、数学、物理、艺术、系统科学和决策科学中的分析方法,整理成可复制、可审查、可组合的 Markdown SKILL.md。
Codex、Antigravity、Claude Code、OpenCode 等 Agent Host 可以直接加载这些文件,用它们来澄清问题、评审写作、设计研究、压力测试决策,或生成更有辨识度的表达。

一、AI Agent 的问题,已经不只是“能不能执行”
现在很多 Agent 工具已经能写代码、改文档、跑命令、生成方案。
但真实工作里,一个更常见的问题是:AI 很快给了答案,却没有先想清楚自己应该从哪个角度判断。
比如:
- 需求没有澄清,就直接进入方案设计;
- 证据不足,却用肯定语气输出结论;
- 把战略判断、写作修改、产品评审和工程实现都压成同一种模板;
- 遇到复杂分歧时,急着给一个折中答案;
- 用“某某风格”包装表达,却没有提供可审查的推理。
这类问题不是单纯靠更长的 Prompt 就能解决。
因为它本质上不是“信息不够”,而是“思维框架没有被显式选择”。
一个复杂问题,通常不应该马上回答,而应该先判断:这是概念澄清问题、证据判断问题、系统建模问题、产品体验问题,还是价值冲突问题?
ArchSight Cognition 想做的,就是把这些思维框架整理成可以被 Agent 读取、复用和审查的工程资产。
二、不是角色扮演,而是学科思维工具
很多人看到 Socrates、Bayes、Newton、Shakespeare、Vignelli 这类名字,第一反应可能是:这是不是一个角色扮演库?
不是。
ArchSight Cognition 的核心原则很明确:
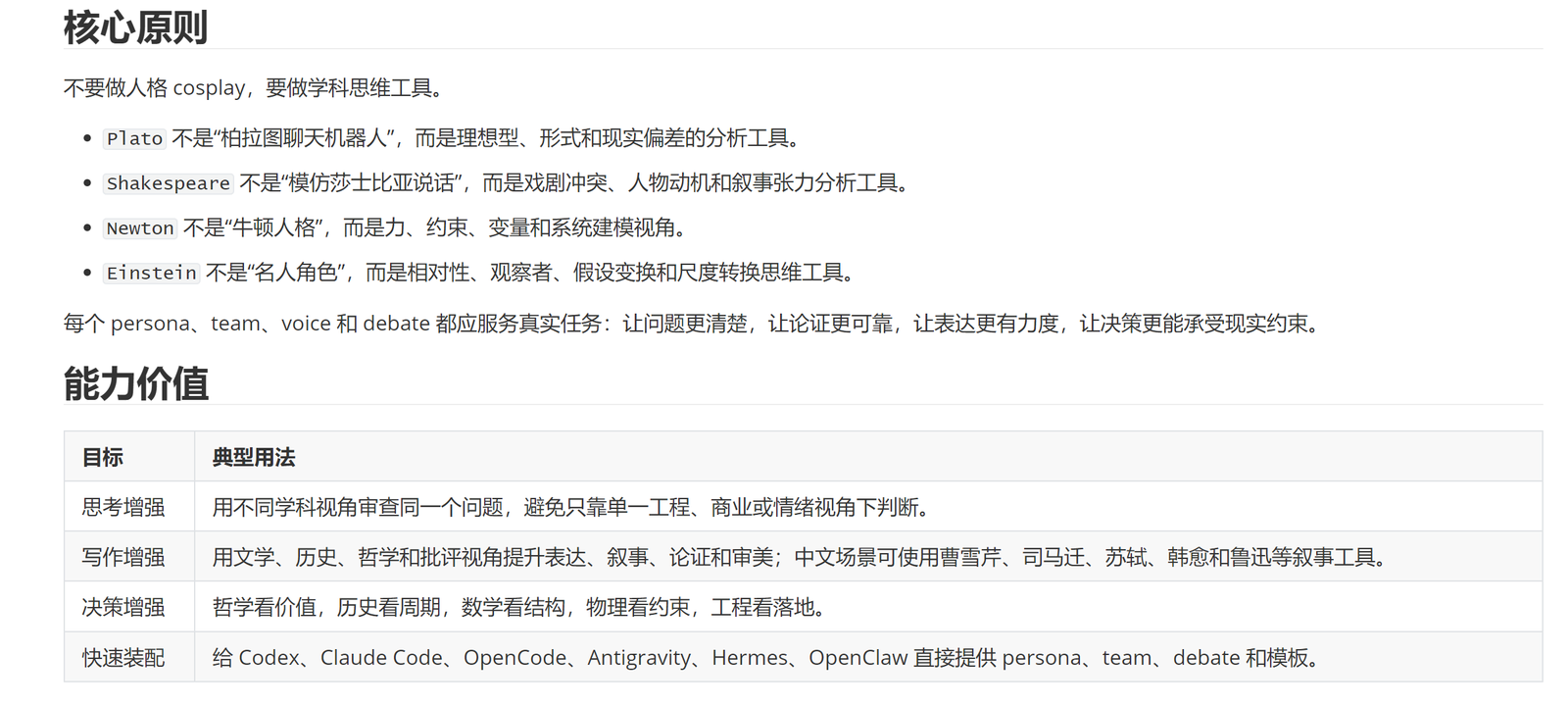
不要人格 cosplay,要做学科思维工具。
这里的 Socrates 不是“苏格拉底聊天机器人”,而是概念澄清、追问前提和暴露矛盾的工具。
Bayes 不是数学家本人在说话,而是证据权重、不确定性更新和置信度判断的工具。
Newton 不是历史人物模拟,而是变量、约束、受力关系和系统建模视角。
Shakespeare 不是为了把文章写得古典,而是用来检查冲突、人物动机、叙事张力和表达能量。
这种设计看起来克制,但对真实工作很重要。
因为 AI 的输出要进入项目协作,就必须能被复核。团队需要知道它使用了什么判断框架,哪些结论来自证据,哪些只是推断,哪些地方还需要人来确认。
三、它解决的是“怎么想”,不是“怎么跑”
很多 Agent 框架解决的是运行时问题:工具调用、任务调度、记忆、权限、上下文窗口、子 Agent 协作。
这些都重要,但 ArchSight Cognition 站在另一个层面。
它不负责调度,不负责记忆,不负责服务进程,也不替代任何 Agent Host。
它只解决一个更轻、更通用的问题:
当 Agent 面对一个任务时,应该加载哪一种认知工具,用什么输出契约完成判断。
例如:
- 问题不清楚时,使用
cogt-think或cogp-socrates; - 重要决策需要复核时,使用
cogt-decide; - 文章像 AI 套话时,使用
cogt-write; - 产品体验需要评审时,使用
cogt-design; - 议题存在强分歧时,使用
cogd-*保留不同立场的张力。
这让 Agent 不必每次从零开始发明分析方法,也不需要把所有任务都交给一个万能提示词。
它更像一组可组合的“思维镜头”:任务不同,镜头不同,输出契约也不同。

四、为什么各行业做 AI 都会遇到这个问题
ArchSight Cognition 是通用项目。它并不绑定某个行业,也不要求使用者先具备某个专业背景。
它面对的是一个更普遍的现象:当 AI Agent 进入真实工作,任务往往不只是“生成一段内容”或“执行一个命令”。
一个看似简单的问题,背后可能同时包含:
- 概念是否清楚;
- 证据是否可靠;
- 目标和约束是否冲突;
- 风险是否被低估;
- 表达是否诚实;
- 决策是否可复核;
- 人和 AI 的责任边界是否明确。
这在很多“行业 + AI”的场景里都会出现。
内容团队用 AI 写文章,问题不只是“写得快不快”,还包括观点是否清楚、事实是否可靠、表达是否诚实。
产品团队用 AI 做用户反馈分析,问题不只是“总结得像不像”,还包括样本是否偏、结论是否可验证、下一步实验是否明确。
教育场景用 AI 辅导学习,问题不只是“能不能给答案”,还包括学生到底理解了没有、学习支架是否合适、是否形成依赖。
企业知识管理用 AI 做问答,问题不只是“能不能搜到文档”,还包括权限边界、过期信息、证据链和人工复核。
研发团队用 AI 写代码,问题不只是“能不能跑”,还包括架构边界、测试覆盖、长期维护和安全责任。
真正需要的是:先判断问题类型,再选择合适的思维工具。
这就比“让 AI 直接给答案”稳得多。
五、一个跨行业都能理解的例子
假设一个团队准备把 AI Agent 引入日常工作:写文章、整理资料、分析反馈、评审方案、辅助决策。
如果直接问 AI:“我们应该全面使用 AI Agent 吗?”
它很可能输出一段很常见的话:
“AI Agent 可以显著提升效率,但也要注意数据安全、质量控制和人工复核。”
这句话没有错,但基本没有决策价值。
换成 ArchSight Cognition 的工作方式,可以拆成几类不同问题:
- 用
cogp-socrates先问清楚“全面使用”指什么:是所有任务都用,还是只在写作、检索、评审、自动化中逐步试点? - 用
cogp-bayes标注证据强弱:哪些收益来自实际项目数据,哪些只是他人经验,哪些还没有被验证? - 用
cogp-newton把约束列出来:时间、权限、数据敏感性、工具稳定性、团队学习成本和复核流程,哪些是硬约束,哪些可以调整? - 用
cogt-write检查输出质量:AI 生成的内容是否清楚、有证据、有结构,还是只是更流畅的空话? - 用
cogt-decide汇总成可行动建议:现在应该全面推广、小范围试点、限制高风险场景,还是先补充规则和验证标准?
这样输出的就不是一段“AI 有利有弊”的泛泛评价,而是一份可以被团队继续讨论的判断结构。
这也是 ArchSight Cognition 的价值:不管是在内容、产品、教育、企业知识管理还是工程研发里,它都不替人做最终决定,而是帮助 Agent 把问题问清楚,把证据摆出来,把风险暴露出来,把下一步验证路径说清楚。
六、项目里有什么
ArchSight Cognition 的核心资产都是可读的 Markdown 文件。
目前主要分为几类:
personas/:单一学科视角,例如哲学、文学、历史、数学、物理、系统、信息、计算、演化、社会制度、教育、科学和艺术设计。teams/:多视角综合工具,例如思考分流、决策评审、写作评审、设计评审、历史战略、科学推理和学习路径。voices/:明确标注的风格化表达工具,只处理口吻,不声称历史人物本人在说话。debates/:结构化分歧工具,用于保留长期议题中的立场张力和反对条件。adapters/:Codex、Antigravity、Claude Code 和 OpenCode 的接入说明。templates/:新增 persona、team、voice 和 debate 的标准模板。

它的命名也比较明确:
cogt-*:team 工具,例如cogt-think、cogt-decide、cogt-write、cogt-design;cogp-*:persona 工具,例如cogp-socrates、cogp-bayes、cogp-newton;cogv-*:voice 工具,例如cogv-kant、cogv-nietzsche;cogd-*:debate 工具,例如cogd-general、cogd-life、cogd-technology。
这套前缀不是为了好看,而是为了让不同 Agent Host 更容易过滤、安装和调用。
七、四类技能可以怎样实测
前面讲的是项目结构。对于第一次接触这类工具的读者,更直观的方式是看真实调用里,它们到底会怎样追问、判断、改写和保留分歧。
我建议用四个行业无关、但和 AI 时代的人机协作高度相关的问题来测试:
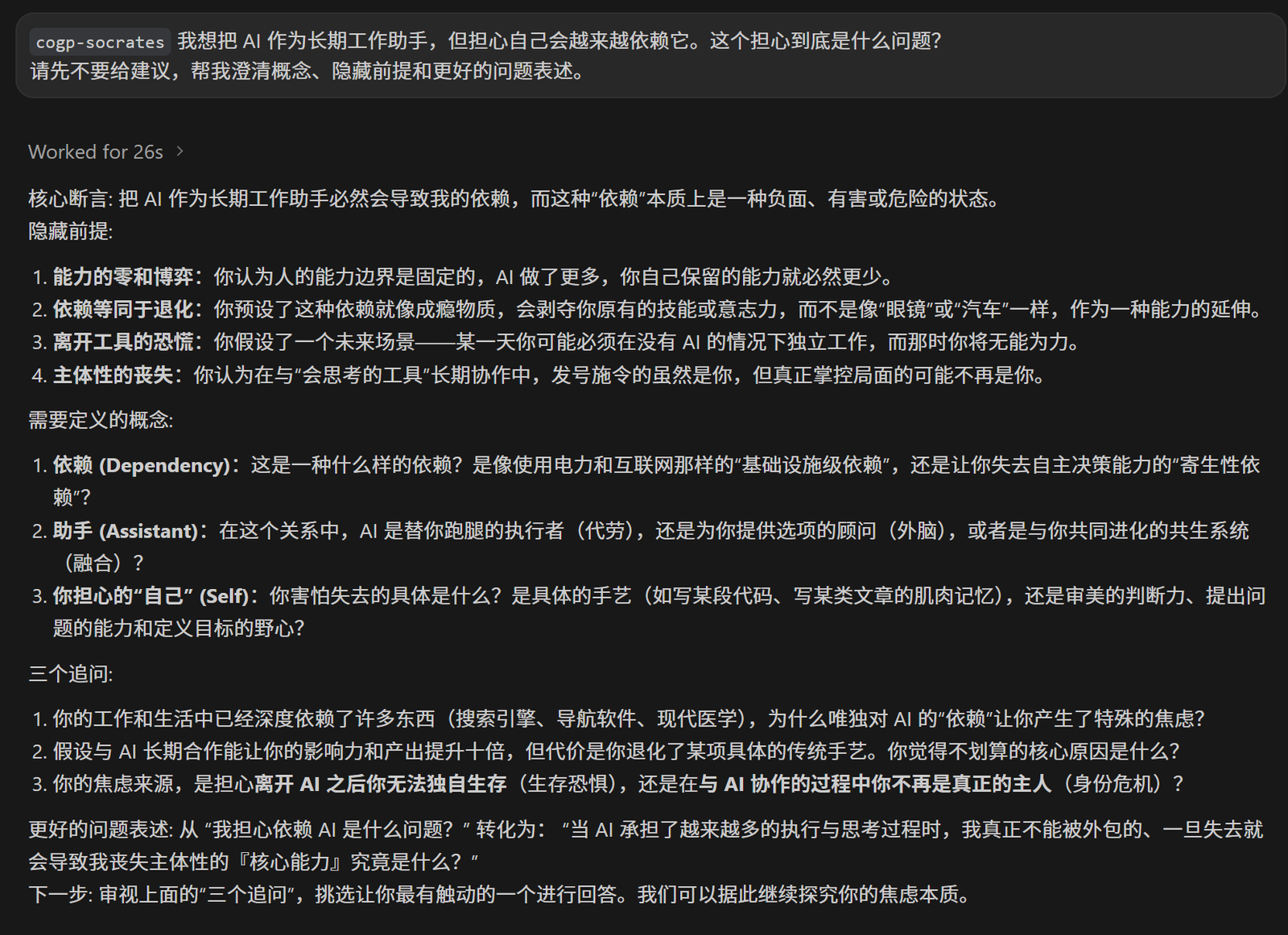
cogp-socrates
我想把 AI 作为长期工作助手,但担心自己会越来越依赖它。这个担心到底是什么问题?
请先不要给建议,帮我澄清概念、隐藏前提和更好的问题表述。
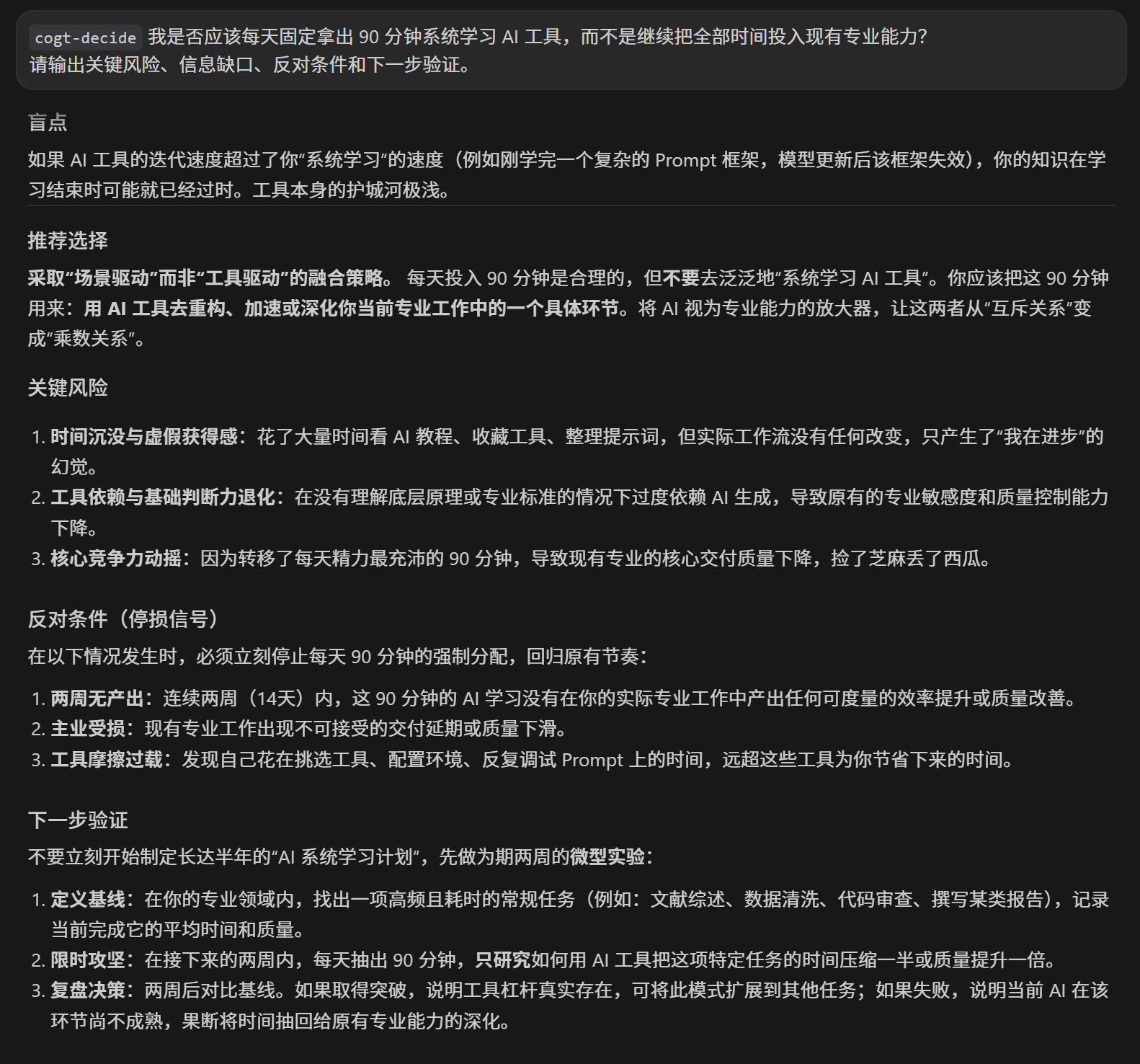
cogt-decide
我是否应该每天固定拿出 90 分钟系统学习 AI 工具,而不是继续把全部时间投入现有专业能力?
请输出关键风险、信息缺口、反对条件和下一步验证。
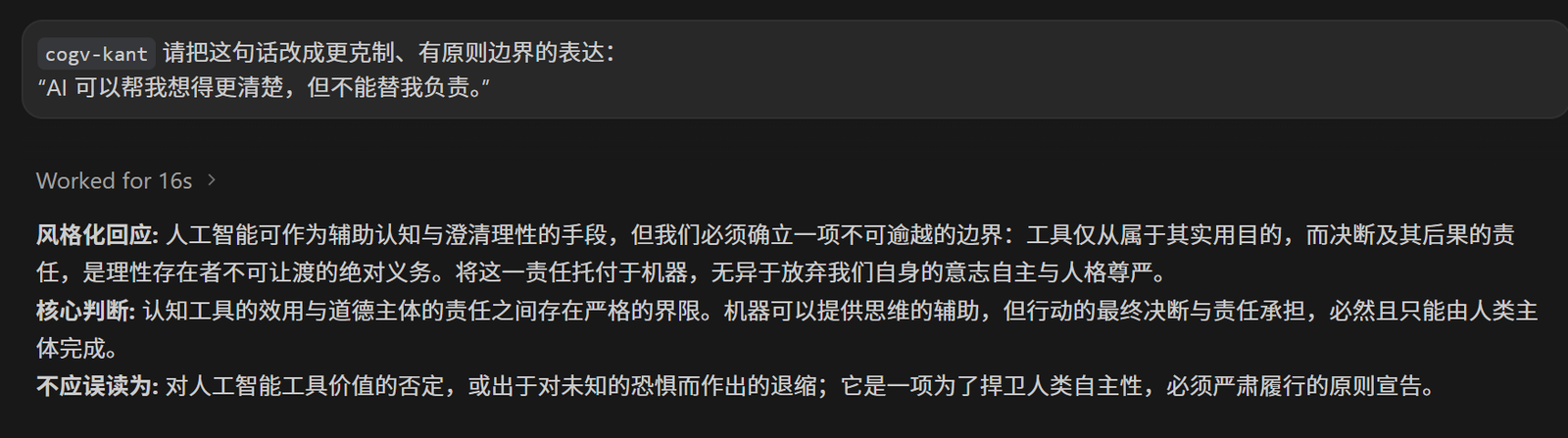
cogv-kant
请把这句话改成更克制、有原则边界的表达:
“AI 可以帮我想得更清楚,但不能替我负责。”
cogd-technology
AI 工具会增强人的思考,还是削弱人的思考?
请用不超过 300 字展开结构化分歧,保留两个强立场和一个验证方法。
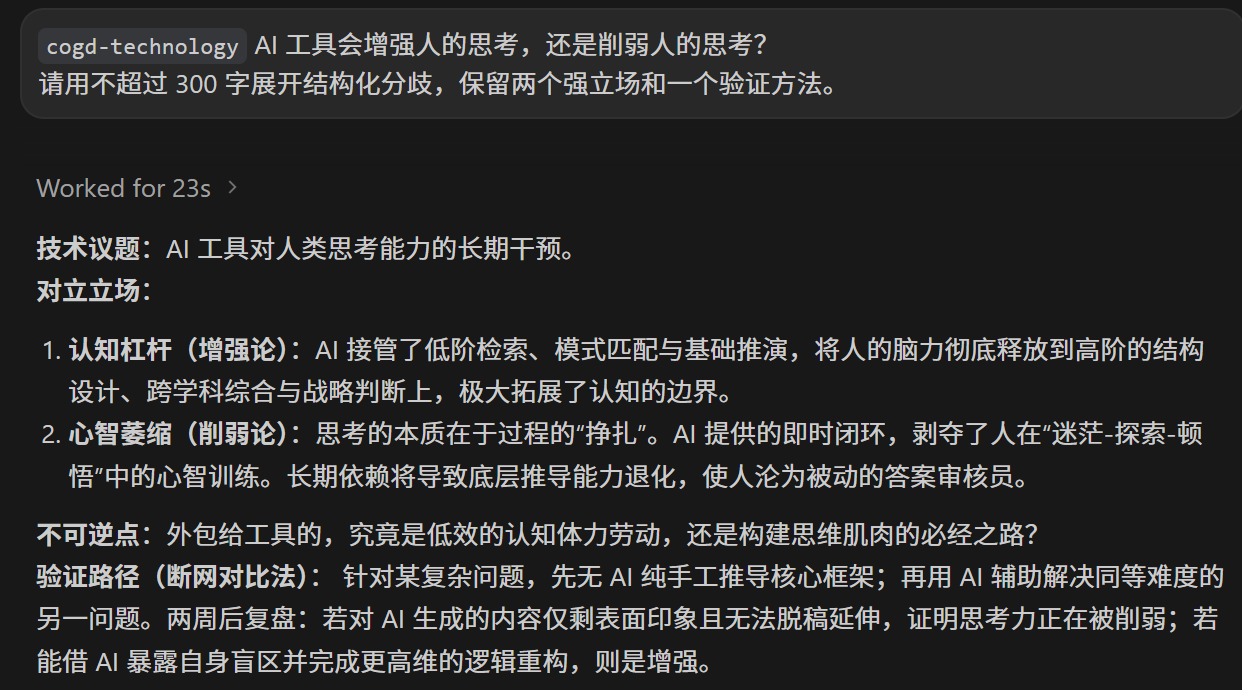
这四个问题分别对应四类工具的边界:
personas/负责给单一学科判断压力,先把问题问清楚;teams/负责多视角综合,最后收束成可执行判断;voices/只负责表达气质,不替代严肃分析;debates/负责保留真实分歧,不急着制造共识。
八、如何开始使用
如果使用 npm / npx,可以一次性安装到当前项目:
npx @archsight/cognition install all
也可以按 Agent Host 分开安装:
npx @archsight/cognition install codex
npx @archsight/cognition install antigravity
npx @archsight/cognition install claude-code
npx @archsight/cognition install opencode
全局安装:
npx @archsight/cognition install all --global
全局分开安装:
npx @archsight/cognition install codex --global
npx @archsight/cognition install antigravity --global
npx @archsight/cognition install claude-code --global
npx @archsight/cognition install opencode --global
新用户可以先从这些入口开始:
cogt-think # 不知道该从哪个视角切入
cogt-decide # 重要决策评审
cogt-write # 写作、文案、叙事评审
cogt-design # 产品、体验、视觉评审
cogp-socrates # 概念澄清
cogp-bayes # 证据和不确定性判断
cogp-newton # 变量、约束和系统建模
一次实际调用可以很简单:
cogt-decide
对这个人机协作决策做一次跨学科评审:
我们计划把 AI Agent 引入团队日常写作、研究和方案评审流程,但担心成员过度依赖 AI 输出。
请输出关键风险、信息缺口、反对条件和下一步验证。
重点不是让 AI 说得更像专家,而是让它的判断过程更可见、更可复核。
九、开源之后,希望它成为可维护的思维资产
ArchSight Cognition 目前仍然是早期版本。
它的价值不在于一次性覆盖所有学科,也不在于把每个 persona 写得多“像本人”。
恰恰相反,它希望把 AI 协作里那些容易被口头化、经验化、临时化的思考方式,整理成可以复制、审查、修改和贡献的项目资产。
这类资产越明确,Agent 的行为就越不容易漂移。
写作时,它知道要检查论证、叙事、清晰度和诚实性。
决策时,它知道要列出约束、风险、信息缺口和反对条件。
产品评审时,它知道要看交互模型、可用性、版式层级和系统一致性。
在各类 AI 协作场景里,它也会更清楚地意识到:证据链、人工复核、责任边界和失败条件,不能被一段流畅文本掩盖。
我希望这个项目能给更多使用 AI Agent 的创作者、工程师、产品团队和研究者一个起点:
不要只让 AI 更快地回答。
也要让 AI 更清楚地思考。
欢迎关注,也欢迎一起交流 AI Agent、跨学科思维工具和可复核的智能协作方式。
项目地址:https://github.com/ArchSightLabs/archsight-cognition npm 包地址:https://www.npmjs.com/package/@archsight/cognition