给 AI Agent 装上判断层:ArchSight Cognition 2.1.0
AI Agent 现在最危险的地方,不是不会干活,而是太愿意马上干活。
需求边界没澄清,它开始写代码。
文章论点没站住,它开始润色。
商业假设没拆清,它开始写计划。
产品问题还没验证,它开始排路线图。
这就是我做 ArchSight Cognition 2.1.0 的原因:给 AI Agent 加一层动手前的判断系统。

如果你只想先判断它值不值得安装,这版的核心变化可以压缩成三句话:
- 从 1.0.0 的“跨学科视角库”,升级为 2.1.0 的“agent 判断层”;
- 新增
cogm-*method,把商业逻辑、管理思维、结构化问题解决、尾部风险等方法变成可调用工具; - 加深 persona 内部维度,让它们更像可复核的思维工具,而不是角色扮演提示词。
我仍然不想把它包装成“提高人类认知的神奇包”。更准确的定位是:
ArchSight Cognition 是给 AI Agent 装上的跨学科判断层。它让 agent 在动手前,先澄清问题、审查假设、选择方法、压力测试决策。
5 月 24 日,我发布过一篇 ArchSight Cognition 开源介绍。那篇文章基于 1.0.0 写成,讲的是“它是什么”。
今天这篇讲 2.1.0,重点是“它和 1.0.0 到底差在哪里,以及为什么你可以真的装上试一次”。
一、从 1.0.0 到 2.1.0,差异在哪里
我对照了 1.0.0 和当前 2.1.0,本轮变化可以压缩成一张表:
| 维度 | 1.0.0 | 2.1.0 |
| --- | --- | --- |
| 项目形态 | 跨学科 persona / team / voice / debate 工具包 | persona / method / team / voice / debate 五类判断工具包 |
| method 层 | 没有 methods/,也没有 cogm-* | 新增 16 个 methods/ 目录和 cogm-* 入口 |
| 工具规模 | 78 个 SKILL.md | 本地当前可见 127 个 SKILL.md |
| 核心能力 | 让 agent 从不同学科视角看问题 | 让 agent 在执行前选择可复用的方法和输出契约 |
| persona 深度 | 主要提供学科视角入口 | 强化研究维度、失败模式、验证逻辑和 anti-cosplay 边界 |
| 现代工作场景 | 以通用思考、决策、写作、设计为主 | 大量补充商业逻辑、管理思维、产品战略、技术领导和组织效能 |
| 产品/组织场景 | 主要靠通用 decision / design / writing team | 新增 cogt-product、cogt-lead 等更贴近产品和技术领导的 team |
| host 适配 | 首批适配 Codex、Claude Code、Antigravity、Hermes、OpenClaw | 扩展到更多 AI agent host,包括 WorkBuddy 等 |
| 治理校验 | 基础开源文档 | 新增治理文档、校验脚本、method 参考材料和 Apache 2.0 / NOTICE 边界 |

更多 host 适配解决的是分发问题:让这套判断层进入更多工作流。真正的核心变化,是 cogm-* method 层。
它把问题从“该用哪个视角看”推进到“该用什么方法拆问题、审查假设、验证结论”。这也是它和普通 prompt / skill 包的差异:不是再多一些任务模板,而是在 agent 执行前增加一层方法选择。
二、为什么需要 cogm-* method 层
1.0.0 已经有 cogp-* persona、cogt-* team、cogv-* voice 和 cogd-* debate。它解决的是“让 agent 从不同视角看问题”。
但很多真正有用的思想模型,并不适合放进 persona。第一性原理、批判性思维、结构化问题解决、尾部风险、商业底层逻辑、管理卫生、冲突中的第三选择,本质上都不是“某个人”,而是一组可执行方法。
所以 2.0 开始新增 methods/,统一用 cogm-* 承接这类内容。它的边界很清楚:来源可以是书籍、管理方法、商业经验、设计原则和长期复盘;进入项目时,必须先去人物中心化,再变成可审查的 method。
这也让 2.1.0 的变化更清楚:cogm-* 承接现代方法论和工作经验,persona 则继续加深任务边界、失败模式、验证逻辑和 anti-cosplay 边界。两者一起构成判断层,而不是角色扮演库。
三、一张图看懂 method 地图
2.1.0 新增和整理的 cogm-*,可以先按任务类型理解:
- 基础问题拆解:
cogm-first-principles、cogm-critical-thinking、cogm-structured-problem-solving、cogm-simplicity-filter; - 决策与风险:
cogm-priority-triage、cogm-causal-failure-analysis、cogm-decision-heuristics、cogm-tail-risk; - 产品商业与组织协作:
cogm-business-logic、cogm-human-centered-interaction、cogm-management-hygiene、cogm-integrative-options、cogm-principled-effectiveness。
如果不知道该用哪个方法,就从 cogm-auto 开始。它会先判断任务类型,再推荐 1 到 3 个合适的 cogm-* 方法。
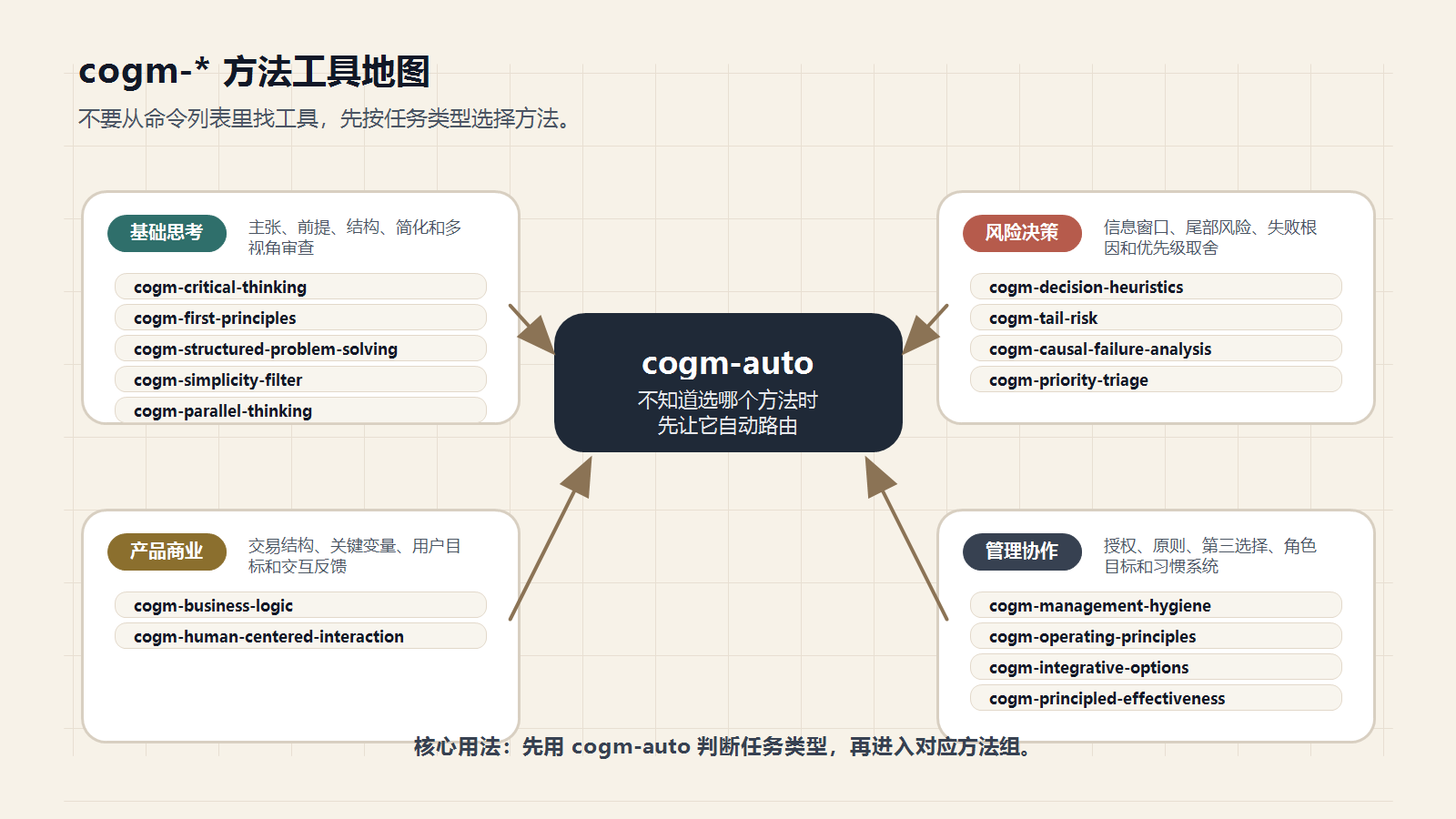
这样看,method 层就不是一串命令名,而是一张工作地图:先判断任务类型,再选择方法,再进入执行。
四、为什么这对 AI Agent 很重要
现在 agent 越来越擅长执行。
但执行力越强,前置判断越重要。
很多失败不是 agent 不够勤奋,而是它太早进入执行:需求边界没澄清,就开始实现;文章论点没站住,就开始润色;产品问题没验证,就开始写路线图;商业约束没拆清,就开始算收益。
cogm-* 的作用,就是在这些场景里把 agent 拉回判断现场:先不要急着完成任务,先选择方法。
persona 给 agent 一个学科视角,method 给 agent 一组操作步骤,team 再把多个视角和方法组合起来,形成写作、决策、产品、设计、技术领导等综合评审。
这个层级一旦清楚,agent 的行为就更容易被复核。它不是在“灵感式回答”,而是在按一个可审查的判断协议工作。
五、治理和校验也变重了
2.1.0 不只是新增工具。
它也把项目治理做重了。
method 工具不只要有 SKILL.md,还要有轻量参考材料:
references/sources.mdreferences/usage-notes.mdreferences/validation-cases.md
npm run validate:skills 会检查 cogm-* 的参考材料,避免只有口号、没有来源和边界。
项目也明确了 persona、method、team、voice、debate 的边界规则:仍在世人物、活跃企业家和个人品牌材料不能直接做成 cogp-* persona 或 cogv-* voice;如果有价值,必须去人物中心化后进入 methods/ 或 team 参考材料。
这件事看起来不性感,但对 agent skills 很重要。
一个判断层如果自己不可审查,就没有资格去审查别的任务。
六、新用户应该怎么理解 2.1.0
不要把 ArchSight Cognition 2.1.0 理解成“127 个 prompt”。
更准确地说,它是一套可安装、可审查、可组合的 agent 判断协议。
如果你只想花三分钟验证它有没有用,不要先浏览全量列表。直接安装,然后拿一个真实问题试。
如果你做产品和商业判断,可以从这些入口开始:
cogt-product
cogt-decide
cogm-business-logic
cogm-tail-risk
cogm-first-principles
可以这样问:
cogm-business-logic
评审这个产品想法的商业底层逻辑:目标用户是谁,交易结构是什么,
关键变量是什么,哪些假设必须先验证?
如果你做写作和表达评审,可以从这些入口开始:
cogt-write
cogm-critical-thinking
cogp-hanyu
cogp-luxun
cogp-sushi
可以这样问:
cogt-write
评审这篇文章是否有空话、论证漏洞和表达遮蔽。
请不要只润色句子,先指出最影响可信度的问题。
如果你要澄清复杂问题,可以从这些入口开始:
cogt-think
cogp-socrates
cogm-structured-problem-solving
cogm-critical-thinking
cogm-auto
可以这样问:
cogm-auto
我现在不知道该用哪种方法分析这个问题。
请先判断任务类型,再推荐 1 到 3 个最合适的 cogm-* 方法。
安装上也保持低摩擦。最简单的方式是:
npx @archsight/cognition install all
如果你使用 WorkBuddy,可以单独安装到个人 skills 目录:
npx @archsight/cognition install workbuddy
我不在这里一一列出所有 host。支持更多 AI agent host 的意义,不是让 README 变成长表格,而是让这套判断层能进入你真实使用的工具链。
七、装上以后,它会自动生效吗
这可能是很多人安装前最关心的问题:我把 ArchSight Cognition 装到全局以后,它会不会在写文章、做架构、想产品思路时自动变成 agent 的一部分?
答案分三层。
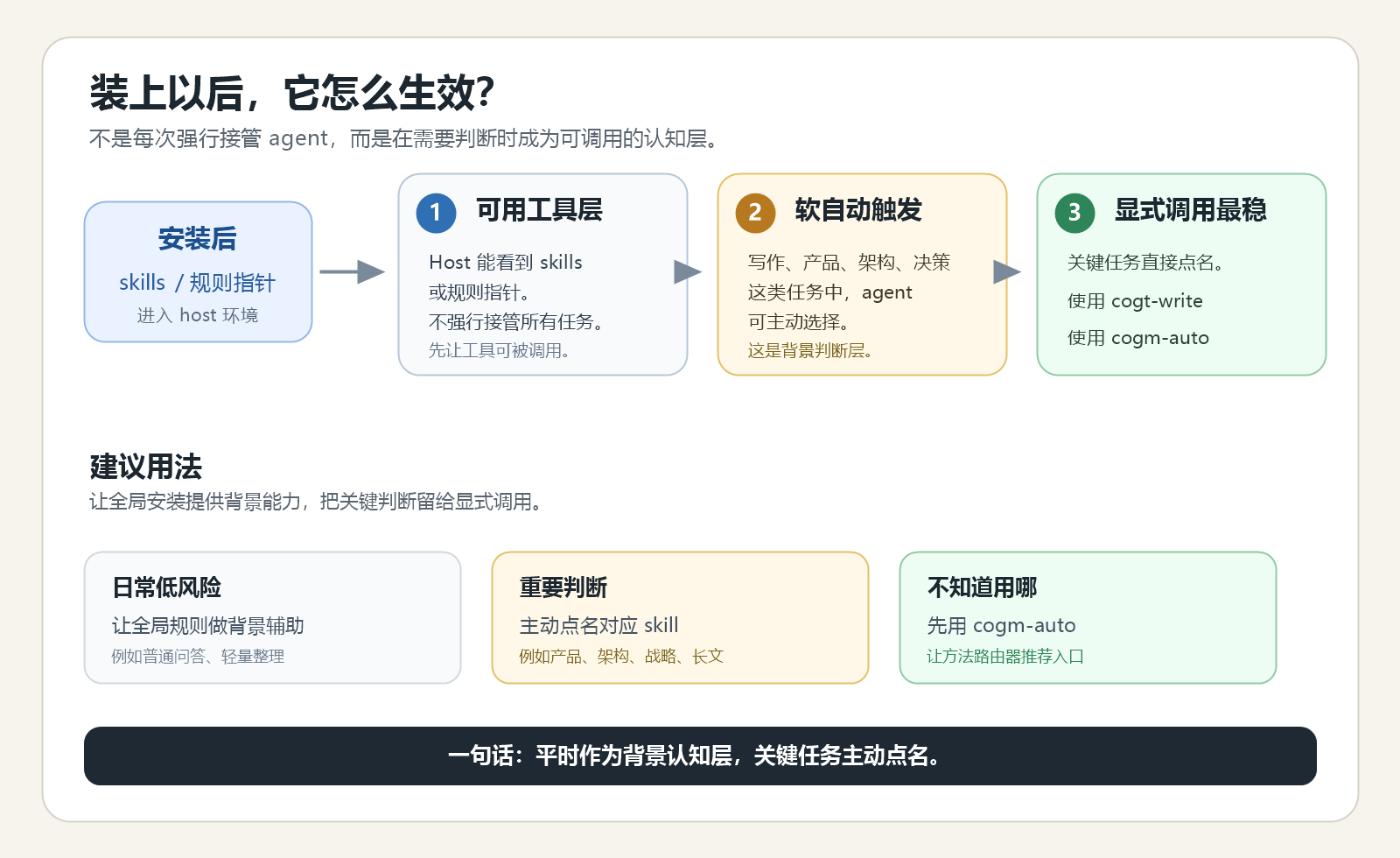
第一,它会变成可用工具。
安装后,Codex、Claude Code、WorkBuddy、Cursor 等 host 可以看到对应的 skills 或规则指针。比如 Codex 会把常用 skills 注册到 CODEX_HOME/skills,并在 AGENTS.md 里写入认知工具路由说明。
第二,它可以软自动触发。
如果 host 会读取规则文件,agent 在遇到写作评审、产品思路、架构判断、决策复盘这类任务时,可以根据规则主动选择合适的认知工具。
但这不是一个完全确定的程序路由。它更像“背景可用的判断层”,由 agent 根据任务理解决定是否加载。
第三,关键任务最好显式指定。
如果你希望它一定触发,最稳的方式仍然是直接点名:
使用 cogt-write 评审这篇文章。
使用 cogt-product 分析这个产品方向。
使用 cogt-lead 评审这个架构和技术组织问题。
使用 cogm-auto 先判断这个任务该用哪些方法。
我不建议让认知工具在所有任务里强行自动触发。那会让 agent 变慢、变啰嗦,也容易过度分析。
更合理的状态是:
- 日常低风险任务,让全局规则作为背景辅助;
- 重要文章、产品、架构、战略判断,主动点名对应 skill;
- 不知道该用哪个工具时,先用
cogm-auto或cogt-think。
ArchSight Cognition 的定位不是接管 agent,而是成为它在关键判断时可调用的认知层。
八、从 1.0 到 2.1,真正变重的是判断层
ArchSight Cognition 1.0.0 解决的是:把跨学科视角整理成 agent 可以加载的 skills。
2.1.0 的变化更明确:新增 cogm-* method,把阅读、方法论和真实工作里的判断动作,沉淀成不依赖人物扮演的工具;同时加深 persona 内部维度,并补上产品、商业、管理、组织和技术领导等现代工作场景。
所以这次更新不是“工具更多了”,而是判断层更完整了。
它不替人做最终决定,也不承诺让 AI 突然变聪明。它只要求 agent 在执行前多做一步:先把问题类型、方法选择、关键假设和边界风险说清楚。
AI agent 不应该只变得更快。它也应该在动手前,先把问题想清楚。